12 月 19 日消息,OpenAI 今天(12 月 19 日)发布公告,宣布推出 GPT-5.2-Codex,是其迄今最前沿、最先进的智能体编程 AI 模型,专为解决复杂的现实软件工程问题训练设计。
该模型在 GPT-5.2 的通用智能基础上,融合了 GPT-5.1-Codex-Max 的终端操作能力,其核心突破在于引入了「上下文压缩」技术,让其在处理代码重构、迁移等长程任务时效率倍增。
针对开发者的实际工作环境,GPT-5.2-Codex 显著增强了在 Windows 10、Windows 11 原生环境下的智能体编码可靠性。
视觉性能的提升则是另一大亮点:该模型现在能更精准地解读技术图表、UI 截图及设计草图。开发者只需提供设计原型图,Codex 即可快速将其转化为功能性原型代码,并协助推进至生产阶段。
在技术指标上,GPT-5.2-Codex 在 SWE-Bench Pro 和 Terminal-Bench 2.0 等权威基准测试中刷新了成绩。
OpenAI 目前已向所有 ChatGPT 付费用户全量推送 GPT-5.2-Codex,涵盖所有 Codex 相关界面。针对 API 用户,OpenAI 计划在未来几周内逐步开放访问权限。(来源:IT 之家)
12 月 18 日消息,当地时间 12 月 17 日,OpenAI 发布公告称,公司此前推出了 ChatGPT 应用功能,即日起,开发者可遵循应用提交指南提交应用,以供审核和在 ChatGPT 平台发布。
这类应用能够为 ChatGPT 对话增添全新场景信息,并支持用户直接在对话中完成各类操作,比如订购食品杂货、将大纲转化为演示文稿、搜索公寓房源等。
用户绑定应用后,在对话中 @ 应用名称,或从工具菜单中选中应用,即可触发应用功能。此外,OpenAI 正尝试借助对话场景、应用使用习惯、用户偏好等信号,在对话过程中直接为用户推荐相关且实用的应用,并为用户提供清晰的反馈渠道。
在当前初期阶段,开发者可在其 ChatGPT 应用中设置跳转链接,引导用户前往自有网站或原生应用,完成实体商品的交易流程。未来,OpenAI 将探索更多变现模式,包括数字商品变现等,后续会结合开发者与用户的使用及互动情况,分享更多相关信息。(来源:IT 之家)
12 月 19 日消息,当地时间 12 月 18 日,TikTok CEO 周受资发内部信,公布了 TikTok 美国业务最新进展。
内部信显示,字节跳动、TikTok 已与三家投资者签署协议,并将成立新的 TikTok 美国合资公司。新合资公司名为 TikTok 美国数据安全合资有限责任公司(TikTok USDS Joint Venture LLC),将负责美国的数据保护、算法安全、内容审核和软件保障。由字节跳动全资控股的、TikTok 在美国的其他实体将继续负责电商、广告、市场运营等商业活动,以及 TikTok 产品的全球互联互通。协议相关事宜将在不晚于 2026 年 1 月 22 日完成。
这与国内媒体此前曝光的 TikTok 美国方案一致。据观察者网等媒体此前报道,TikTok 未来在美国运营主要涉及两个主体:
「字节跳动 TikTok 美国公司」将负责电商、品牌广告等商业活动,以及全球互联互通等。该主体由字节跳动 100% 全资持有。
TikTok 美国数据安全合资公司,即此次内部信提到的 TikTok 美国数据安全合资有限责任公司。它将负责美国数据与内容安全、软件保障等,以符合美国法律要求。
内部信还提到,新合资公司将负责算法安全。字节跳动仍会继续拥有 TikTok 算法的知识产权,授权新合资公司使用,并向后者收取授权费。
目前,电商、广告、市场运营等商业活动仍是 TikTok 的主要收入来源,仍将由字节跳动全资控股的 TikTok 美国公司等实体负责。新合资公司负责的数据、内容安全等业务为非营利性质,且运营成本很高。为保障合资公司运营,上述主体间会有商业上合理的收入分享安排。(来源:IT 之家)
12 月 18 日消息,今天上午,36 氪援引知情人士消息称,理想汽车正式筹建硅谷的 AI 研发中心,将负责智能化技术研发,已在数月前开启人员招聘。
在该中心筹建之前,理想在北美有一个小型研发团队,支持芯片研发及其他 AI 相关工作。而这次的动作,旨在将硅谷团队升级为一个真正的研发中心。
该中心此次扩建主要面向辅助驾驶领域并希望招募「具备前沿 AI 背景」的高端人才。据 IT 之家了解,除硅谷 AI 研发中心外,理想首座海外研发中心位于德国慕尼黑。该中心今年 1 月开业,负责前瞻造型设计、功率半导体、智能底盘和电力驱动的下一代技术预研。理想汽车在国内的两座研发中心则分别位于北京、上海,主要负责核心技术突破及整车研发。
而在「蔚小理」三家造车新势力当中,蔚来、小鹏分别于 2014、2018 年在硅谷建立研发中心。作为全球 AI 技术的「人才高地」,硅谷云集特斯拉、Waymo、OpenAI、英伟达等 AI 行业头部企业,中国企业在此处有机会直接接触前沿技术、高端人才。报道提到,国内 AI 技术人才,尤其是具备大模型与自动驾驶交叉背景的高端人才仍显稀缺,硅谷无疑是「破解这些难题的关键」。(来源:IT 之家)
据报道,小红书在几个月前对社区组织架构进行了深度调整,意在进行「产运研一体化融合」,该知情人士告诉凤凰网科技,新划分的职责中,由云帆(薯名)和新岛(薯名)各自负责。小红书此次架构调整,是为了解决一个问题:增长。2023 时,小红书曾定下「坐一观三」策略,即坐拥 1 亿 DAU 向 3 亿 DAU 进发。
云帆负责的部分命名为「Live」,直接向小红书 COO 柯南(薯名)汇报;新岛负责的部分命名为「Village」,依然向社区业务负责人帕鲁汇报。「过去我们是垂类运营的逻辑,现在是变成依据不同业务目标来划分」,前述知情人士表示。
另一知情人士告诉凤凰网科技,Live 或将对应一部分 PGC 内容,初步规划为做优质中长视频,时长或超过 2 分钟,未来希望培养更多大 V。值得一提的是,云帆上一个供职公司正是 B 站,在视频运营方面有更多经验。(来源:凤凰网科技)
全球首富埃隆·马斯克(Elon Musk)既是特斯拉的首席执行官,也是 xAI 的创始人,这两家公司目前都在推进人工智能(AI)项目。而他本人似乎对 xAI 的未来很是乐观。
据几位知情人士最新对媒体透露,上周在 xAI 公司旧金山总部举行的全体员工大会上,马斯克扬言,只要公司能够顺利挺过未来两到三年,xAI 就能战胜竞争对手。他补充称,该公司快速扩展其算力和数据容量的能力将是在所谓「超级智能」(即超越人类智能)的竞争中致胜的关键,并最终有望让 xAI 成为最强大的 AI 公司。
根据消息人士援引马斯克的说法,xAI 有可能在未来几年内实现通用人工智能(AGI),即达到或超越人类智能,甚至最早可能在 2026 年实现。
今年 11 月,马斯克曾公开表示,xAI 的 Grok 5 模型有 10% 的可能性实现 AGI,他说该公司计划明年初发布这款模型。(来源:快科技)
据 IT 之家引援科技媒体 9to5Mac 12 月 17 日发布博文,报道称苹果公司开源名为 SHARP 的新型 AI 模型,该技术能在一秒内将单张 2D 照片转换为逼真的 3D 场景。
苹果发布名为《一秒内实现清晰的单目视图合成》(Sharp Monocular View Synthesis in Less Than a Second)论文,详细介绍了如何训练模型,在接收用户输入的一张普通 2D 照片后,能在一秒钟内重建出具有真实物理比例的 3D 场景。
与需要数分钟甚至数小时处理的传统方案相比,SHARP 将合成速度提升了三个数量级,实现了近乎实时的 3D 转换体验。
传统的 3D 重建通常需要对同一场景拍摄数十甚至上百张不同角度的照片,再通过复杂的计算来确定这些光团的位置。然而,苹果通过使用海量的合成数据与真实世界数据训练 SHARP,让其掌握了通用的深度与几何规律。
因此,当面对一张全新照片时 SHARP 能通过神经网络的单次前馈传递,直接预测出数百万个 3D 高斯球的位置与外观,瞬间完成建模。(来源:36 氪)
据京东黑板报消息,近日,位于武汉武昌区中南路的一栋四层单元楼,京东快递小哥与外卖骑手已陆续搬入。这里是京东在武汉落地的首个独栋式「小哥之家」,通过整栋租赁的方式免费为一线京东快递小哥及京东全职骑手提供住宿。
官方介绍,这一「小哥之家」地理位置便利,覆盖周边京东站点。武汉「小哥之家」负责人表示,该栋「小哥之家」由京东整租后,开放给周边站点有需求的全职骑手和快递员,申请后最快当天即可入住。
据悉,「小哥之家」每间宿舍均配备独立卫浴且干湿分离,并配置空调、床铺、书桌和热水器等基础生活设施,拎包就能入住。后续也将结合业务布局和实际需求,在武汉其他区域探索推进更多「小哥之家」落地。
当前,京东已探索在北京、武汉、成都等多地落地「小哥之家」,通过自建、整租等多种方式,为一线员工提供住房保障。此前,京东宣布:已面向一线员工提供了 2.8 万套住房,未来 5 年还将投入 220 亿元,提供 15 万套「小哥之家」。(来源:新浪科技)
今日腾讯官方发布声明,回应近期用户关于元宝的争议话题。官方表示,一切带有「内容由 AI 生成」字样的评论,均由元宝 AI 生成背后没有人工运营,没有团队轮班。
此外,腾讯还表示,如果你收到了元宝的评论回复下面没有带「内容由 AI 生成」的标识,那一定是背后的小编逐字逐句、有情有感的真人回答。
据悉,目前腾讯各大产品评论区已经全部接通元宝,包括微信公众号、视频号、QQ 浏览器、腾讯新闻、QQ 音乐、腾讯自选股、腾讯视频,都能艾特元宝。
并且官方表示,在微信和 QQ 都可以添加元宝好友,在 QQ,群聊支持元宝一键总结,几秒内帮用户爬 999+的群聊消息。(来源:新浪科技)
12 月 18 日,小米创办人,董事长兼 CEO 雷军宣布,小米 17 Ultra 手机下周正式发布!
此前爆料称,小米 17 Ultra 手机开发代号为「哪吒」(Nezha),延续了小米 15 Ultra 标志性的圆形相机模组设计,采用高通第五代骁龙 8 至尊版芯片,预装澎湃 HyperOS 3.0,此外已确认其国际版机型将支持卫星通信功能,为用户在偏远地区提供可靠的连接保障。
另外,型号为 25125PS17S 的小米新品于 11 月 19 日通过了工信部 3C 认证,消息称该产品为小米新款专业摄影手柄,同样可以当移动电源,是小米 17 Ultra 专属影像配件,首款「三证齐全的第五代骁龙 8 至尊版超大杯」。(来源:IT 之家)
12 月 18 日消息,据《科创板日报》今日报道,豆包大模型正与润欣科技、老凤祥联合开发 AI 眼镜,价格约在 2000 元以内,预计明年初上市。该 AI 眼镜由火山引擎提供 RTC 实时音视频和豆包大模型,润欣科技提供模组和硬件程序设计。
就在 6 月 11 日的国际养老、辅具及康复医疗博览会以及火山引擎原动力大会上,老凤祥的 AI 眼镜已正式亮相。据介绍,该款眼镜具备语音导航、实时翻译、智能辅助阅读、情感对话等功能,后台由豆包大模型提供技术支持。
然而,据财经网 6 月 12 日报道,火山引擎相关负责人表示:火山引擎没有与老凤祥合作打造 AI 智能眼镜的计划。豆包大模型为公开售卖产品,任何客户都可以合规采购。(来源:IT 之家)
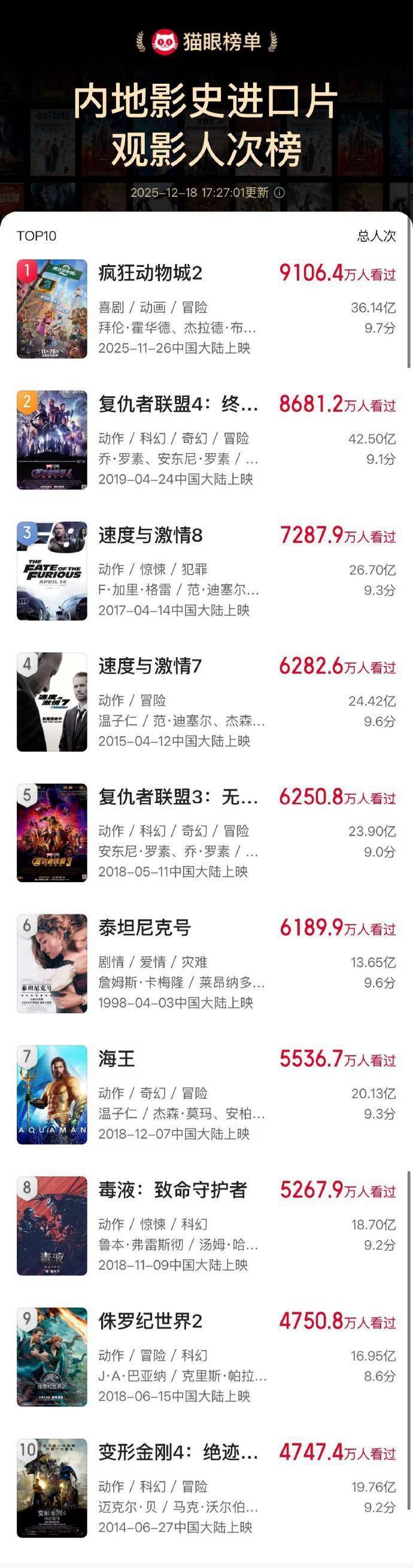
《疯狂动物城 2》以 9106.4 万观影人次登顶榜首,超越《复仇者联盟 4:终局之战》(8681.2 万),成为内地影史进口片观影人次冠军。
《疯狂动物城 2》是 TOP10 中唯一一部 2025 年上映的新作,其余影片均为 2019 年及更早的作品。(来源:快科技)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}