作者| 金光浩
编辑| 靖宇
2026 年 2 月,OpenClaw 火了。
整个互联网圈子被龙虾刷屏的时候,我和大多数人一样,注意力全在这条明线上:2 月底到 3 月,几乎所有互联网大厂在同一时间推出了自己的 OpenClaw 平台,一场龙虾大战轰轰烈烈地打响。
但进入 3 月底,龙虾的热度开始猛的往下掉。
我重新翻了一下这段时间上线的产品,发现了一条暗线,只是当时被龙虾的声量盖住了:
3 月 9 日,腾讯上线 WorkBuddy,定位 AI 原生桌面智能体工作台。3 月 17 日,阿里发布钉钉「悟空」,打的是企业级 AI 原生工作平台的旗号。3 月 19 日,字节把飞书 aily 做了一次全面升级,变成全新的智能体平台。3 月 23 日,百度推出 DuMate 搭子,面向个人和团队的桌面级 AI 智能体。
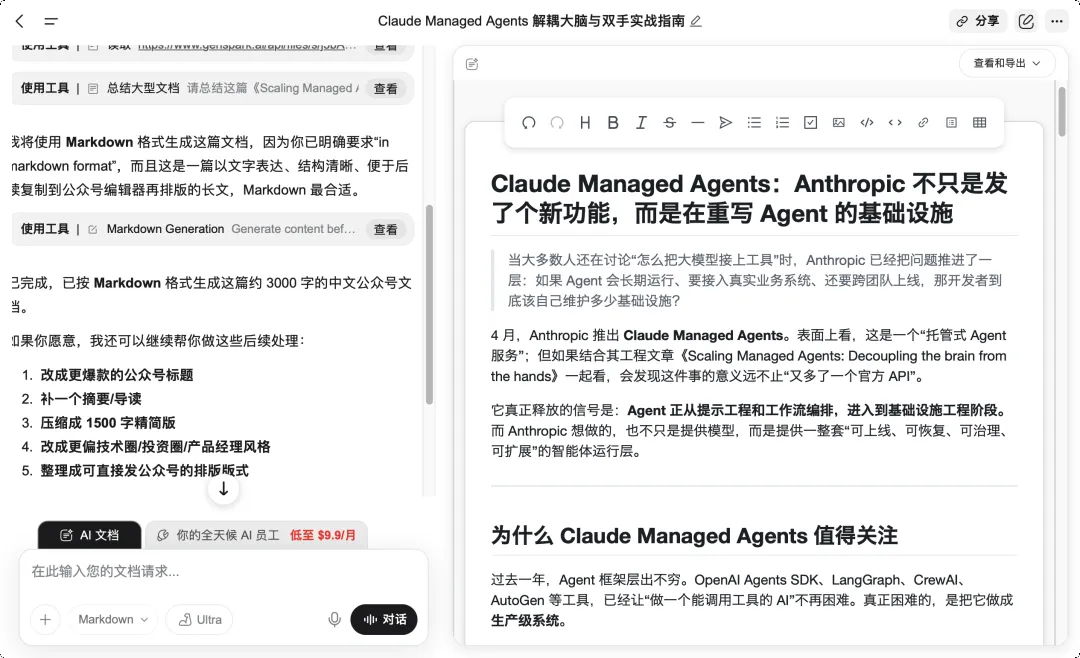
然后到了 4 月 8 日,Anthropic 发布了 Claude Managed Agents。发布第二天,美股软件股集体重挫,SaaS 指数单日跌了 5.5%。
细细看这条时间线,一个爆火的赛道浮出水面。
2026 年,所有大厂都在押注同一个赛道: AI 员工。
OpenClaw 的爆火,让 AI 真正走进了每个人的生活。而大厂们从中看到了一个更大的机会: 让 AI 走进企业,去节省人力成本,或者提升人力效率。
就在 Claude Managed Agents 发布的同一天,还有一个产品同步面向全球发布,它就是今天的主角: GenSpark 4.0。
GenSpark 4.0 愿景|图片来源:Genspark
它的愿景是: 让 AI 员工无处不在。
我花了几天时间,深度体验了这款产品,体验完之后我有一个很强烈的感受:
Anthropic CEO 预言的海外裁员浪潮,可能真的快来了。
GenSpark 发展和转型
先聊聊 GenSpark 这家公司,它在成为黑马前,有一个艰难的转型史:
2024 年 6 月,GenSpark 发布了第一款产品,做的是 AI 搜索,积累了大约 500 万用户。
但团队很快意识到一个问题:人们搜索信息,绝大多数时候目的并不是「获取信息」本身,而是为了完成某个具体的任务。这个认知让 GenSpark 开始调整方向:不仅仅提供信息,更要帮用户把事情做完。
2025 年 4 月,他们推出了 Super Agent 套件,产品正式从 AI 搜索向通用 AI Agent 转型。
效果立竿见影,推出 45 天内 ARR 就达到了 3600 万美元。
2026 年 1 月底,他们的 Workspace 2.0 发布,主打「Don't Type,Just Speak」,把交互方式从文字提示切换到语音优先,试图重塑知识工作者的办公模式。
到这个节点,公司 ARR 已经突破 1 亿美元,B 轮融资扩展到 3 亿美元。
2026 年 3 月 12 日,GenSpark 3.0 和 Genspark Claw 一起发布。他们的口号很有野心:「你不再与 AI 一起工作,而是雇佣 AI 为你工作」。
这一版完成了从「AI 工具」到「AI 员工」的品类转变,ARR 突破 2 亿美元,B 轮融资扩大到 3.85 亿美元,估值接近 16 亿美元。
然后仅仅过了不到一个月,4 月 8 日,他们正式推出了:GenSpark 4.0。
为什么选择 Genspark|图片来源:Genspark
这一版他们真正找到了自己的使命:AI 应该适配你已有的工作方式,而不是要求你围绕 AI 重组工作流程。
所以在 4.0,他们打通了原生集成,桌面、Office、日历、工作流,支持本地文件访问和应用内操作,追求的是「你感觉不到 AI 的存在,但它一直在帮你做事」。
从搜索到 Agent,从工具到员工,GenSpark 用两年时间完成了三次关键转型。
而每一次,都精准踩在了 AI 发展的变化上。
为什么说 GenSpark 是这个赛道的王者?
说回 Agent 员工这个赛道,开头提到的那些大厂产品,每一家都有自己的打法。
但我花时间对比了一圈之后,发现 GenSpark 在一些关键问题上,想得确实更深。
我试着从第一性原理的角度来拆解这个问题:
如果要设计一个能真正充当 AI 员工的产品,它到底需要具备什么?
我觉得至少要满足三个条件:
第一,企业级的运行环境。
AI 员工得能和真实的人交流,能接收文件,能在一个稳定的环境里持续运转。GenSpark 4.0 在这一层做得很到位。它可以和联系人直接对话,并且原生集成了 MyClaw,不需要用户自己去安装 OpenClaw 再配置到飞书或微信。
Genspark 界面|图片来源:Genspark
这一点看起来只是个简单的功能,但对于普通用户意义很大:对接 OpenClaw,无论飞书还是微信的文档对接流程写得多清晰,任何一步配置对于非技术用户来说都是门槛。
GenSpark 把这个配置环节直接砍掉了,说明他们眼里真的非常重视用户。
第二,丰富的工具体系:提供各种 AI 员工得能用工作中真实在用的软件。
GenSpark 4.0 对接了 Notion、邮件、GitHub、文档服务等一系列工具,覆盖了知识工作者日常高频使用的场景。
Genspark 邮箱界面|图片来源:Genspark
还有打工人的三件套:PowerPoint、excel、word
Genspark 三件套界面|图片来源:Genspark
第三,也是我觉得最容易被忽视的一点:人类高效工作的交互方式。
GenSpark 4.0 提供了工作流功能,你可以把各种应用的 CLI 和能力串联成动作流,也可以通过对话直接创建 Skill。
Genspark 工具界面|图片来源:Genspark
而对比开头提到的产品,目前只有钉钉和飞书本身自带企业级运行环境,同时,如果你想要创建 Skill,这些产品基本只能通过对话让 AI 自动生成,人类很难介入迭代过程。 换句话说,用这些产品,目前你还没办法把自己的工作经验真正变成一个可复用、可优化的 Skill。
但这可能才是这类工具真正的价值。
而 GenSpark 4.0 在这个层面给出了更好的方案:
你可以方便地参与 Skill 的构建和调整,让工作经验真正沉淀下来。
Genspark 工作流界面|图片来源:Genspark
整体体验下来,我得出一个判断:
GenSpark 在 AI 数字员工的产品理念上, 确实领先了国内至少「三个月」。
开始实测
理念领先,GenSpark 的效果如何呢?
让我们开始用真实的工作,来实测效果吧。
我日常的工作流程大概是这样的:研究各种 AI 工具,体验产品,形成判断,然后撰写文章。GenSpark 4.0 对我的帮助有多大?我决定用一个完整的任务来测试。
今天我想研究的课题是:「Claude Managed Agents 会对软件行业产生什么冲击?」
GenSpark 4.0 有免费的体验额度,我直接从这里开始。
Genspark 界面|图片来源:Genspark
当然,最好的方式是创建一个以主题为核心的工作区:
Genspark 工作区界面|图片来源:Genspark
工作区可以添加文件,也可以邀请团队成员协作。在这个工作区里对话,就可以调用 GenSpark 4.0 内嵌的多种智能体来完成工作。
Genspark 智能体界面|图片来源:Genspark
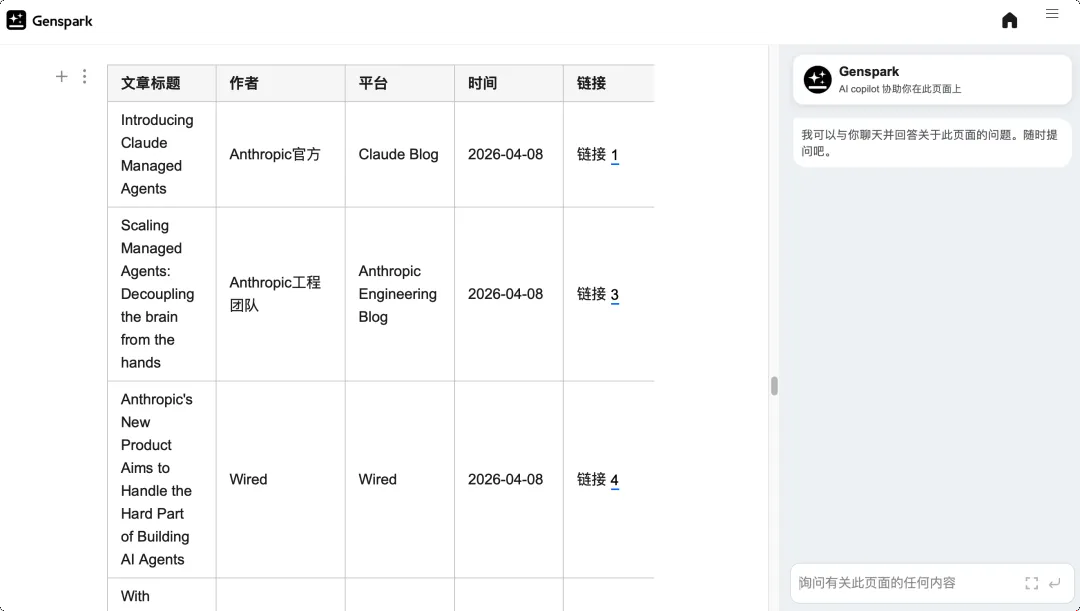
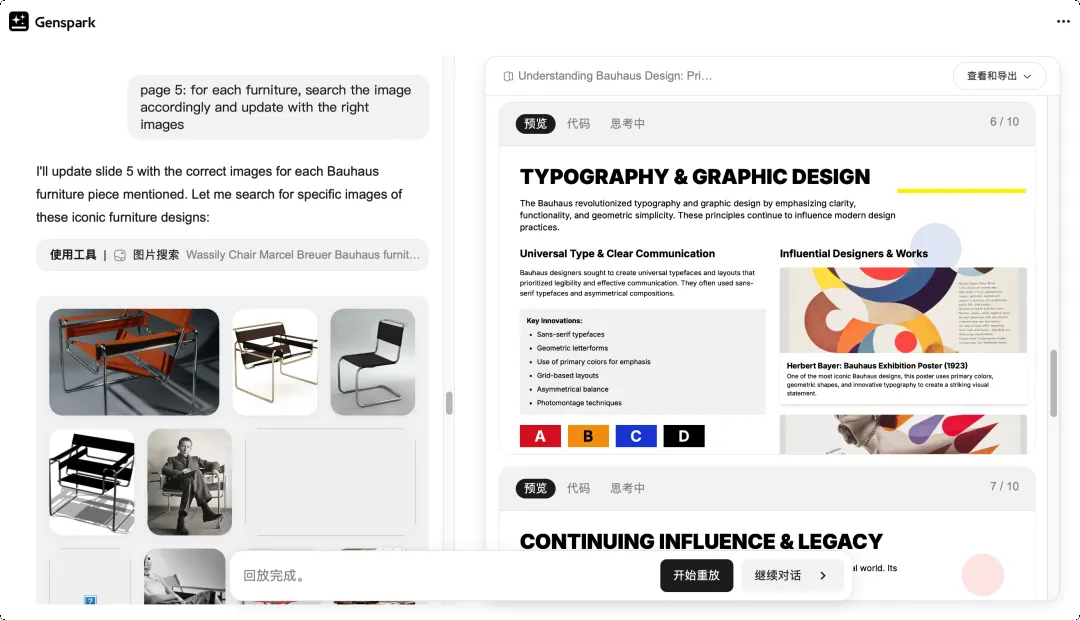
第一步,我从 Anthropic 官网下载了 Claude Managed Agents 的技术文档,导出为 PDF。
https://www.anthropic.com/engineering/managed-agents
Anthropic 文档界面|图片来源:Anthropic
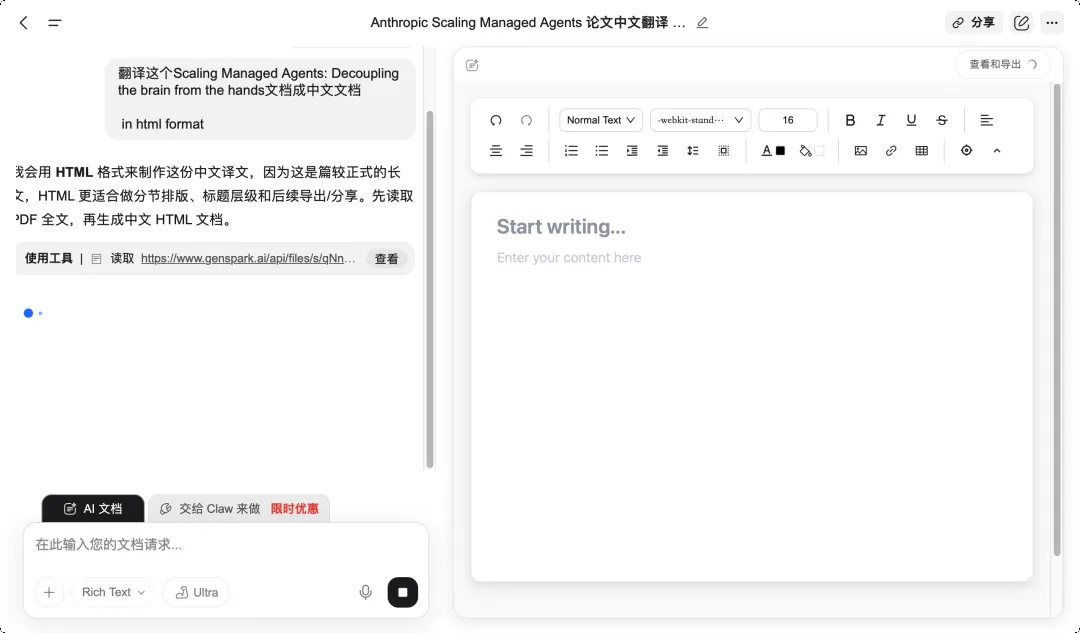
然后用 GenSpark 的撰写文档功能,让它帮我翻译这份 PDF。
Genspark 文档界面|图片来源:Genspark
它很快开始处理,没过多久翻译就完成了。
Genspark 翻译界面|图片来源:Genspark
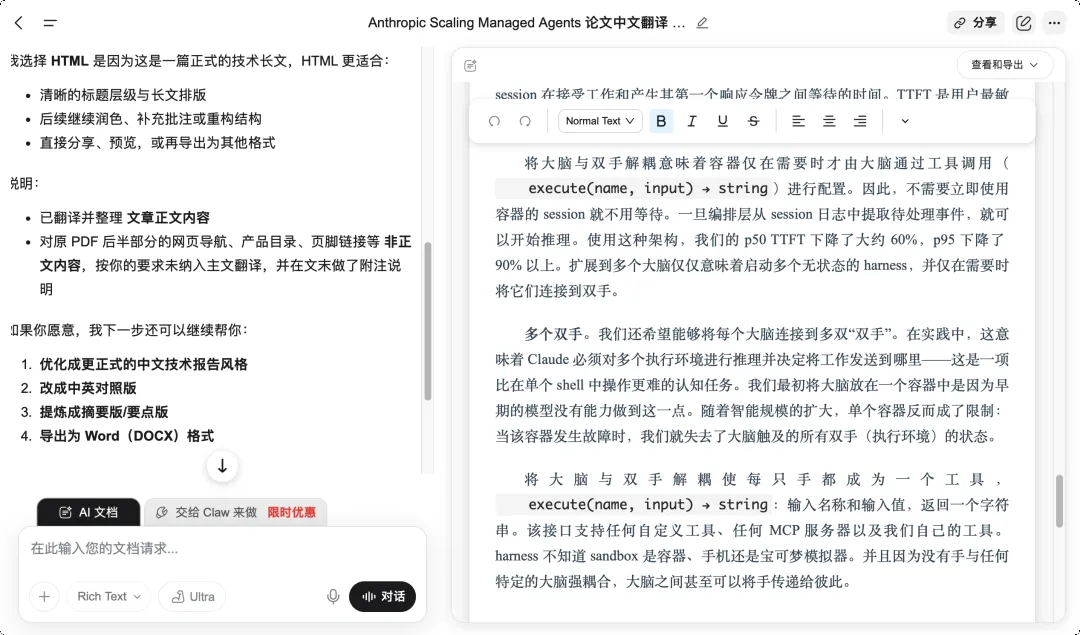
翻译质量让我挺满意的,技术术语的处理很准确,可读性也不错。
Genspark 翻译界面|图片来源:Genspark
拿到第一手资料后,我开始做更广泛的深度研究。
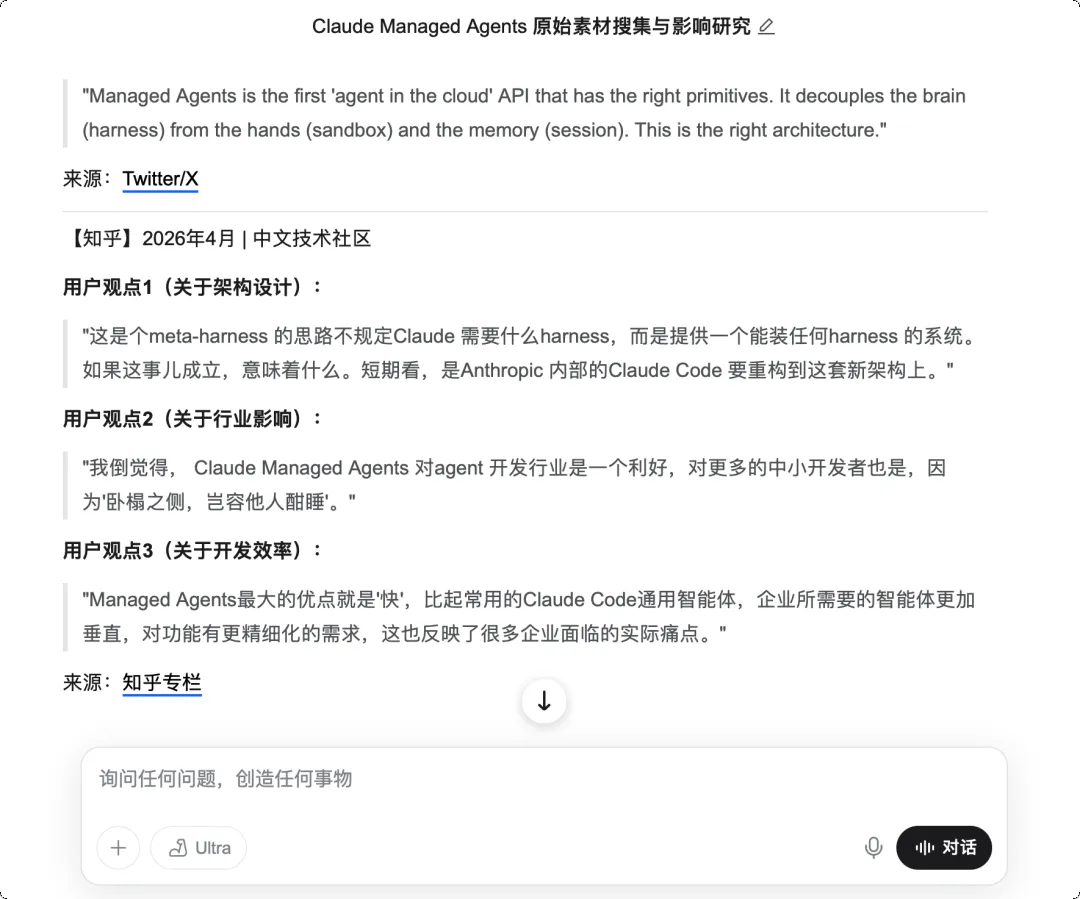
我让 GenSpark 帮我全面调研「Claude Managed Agents」这个话题。
Genspark 深度研究界面|图片来源:Genspark
接下来的过程让我有点意外:
它在知乎、Twitter/X 上广泛收集了各方观点和判断,然后输出了一份完整的研究报告。
Genspark 深度研究界面|图片来源:Genspark
更有用的是,你可以像用 IMA 一样,对这份报告进行各种追问,深入挖掘你关心的细节。
Genspark 深度研究界面|图片来源:Genspark
我把关于这个产品的所有疑问都问了一遍,得到的回答质量都相当高。
Genspark 深度研究对话界面|图片来源:Genspark
素材准备好了,接下来就是写稿。
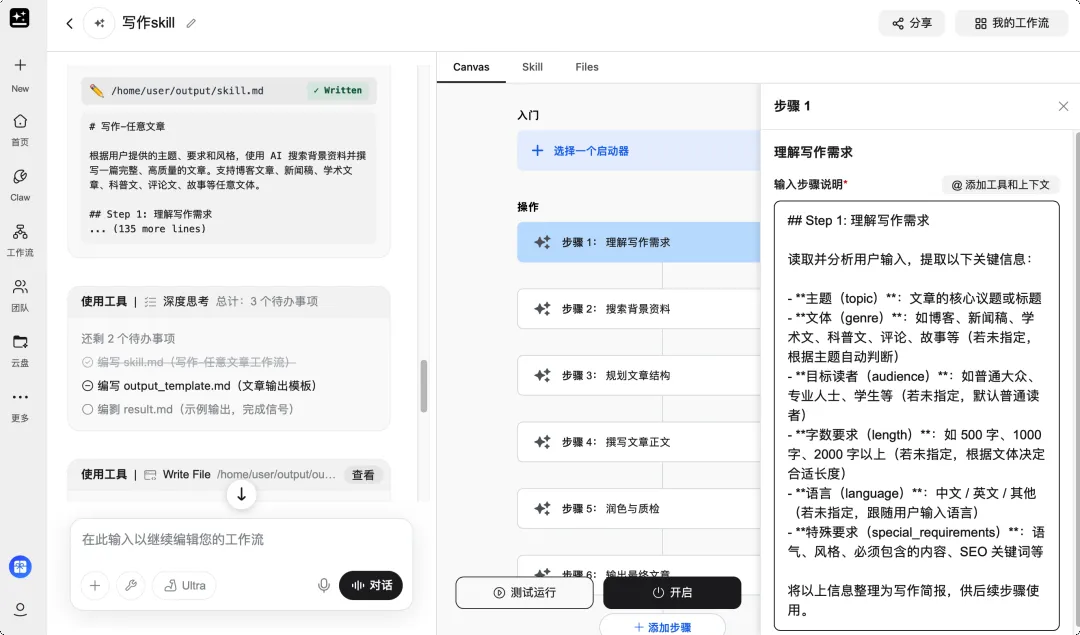
在动笔之前,我先做了一件事:创建一个写作 Skill。
通过多轮对话的方式,GenSpark 调用 OpenCode 帮我生成了一个定制化的写作 Skill。
这个 Skill 融入了我的写作风格偏好、文章结构习惯和排版规范。
Genspark 的 Skill 界面|图片来源:Genspark
然后我用这个 Skill 开始生成文章初稿。
Genspark 文档界面|图片来源:Genspark
不得不说,出来的稿子质量让我有点震撼:
Genspark 文档界面|图片来源:Genspark
结构清晰,论据充分,行文节奏比我自己从零写要流畅得多。
Genspark 文档界面|图片来源:Genspark
全程,我没有用任何其他工具:
从资料收集、翻译、深度研究、素材整理到初稿生成,都在 GenSpark 4.0 一个产品里完成。
我唯一需要学习的,就是 GenSpark 4.0 本身,而学习它,我只用了 50 分钟。
顺带提一句 GenSpark 的视觉体验:它不仅在工具能力上做得领先,连界面设计和交互审美也下了功夫。整个使用过程中,你能感受到产品团队对视觉细节的追求,这在 Agent 类产品里并不常见。
Genspark PPT 演示界面|图片来源:Genspark
GenSpark4.0 的独特价值
实测完之后,我开始想一个问题:
做 AI 员工,到底需要做好的是什么?
Claude Code、OpenClaw、Codex 这些工具,核心是给 AI 提供 Harness 环境。 所谓 Harness,就是让 Agent 能最高效地使用各种工具,完成具体任务。这些产品解决的是「如何让 AI 更好地工作」的问题。
GenSpark 做的事情刚好反过来。
它给人类提供了工作的 Harness 环境,解决的是「如何让人最高效地使用 Agent,完成复杂的工作任务」。
GenSpark 4.0 考虑的是: 怎么最方便地给工作中的人提供一站式的 Agent 服务?怎么让用户把工作经验变成可复用的工作流?怎么让用户不需要在多个工具之间跳来跳去?
Genspark PPT 工具介绍界面|图片来源:Genspark
这个差别看起来只是视角的切换,但落到产品层面,差异非常大。
传统的 Agent 产品,你可能需要打开一个工具做研究,再切到另一个工具写文档,再用第三个工具做协作。每一次切换都是效率损耗,都是注意力的中断。
GenSpark 4.0 把这些环节全部收拢到一个产品里, 创建工作区、添加文件、邀请成员、调用智能体、生成 Skill、执行工作流,所有事情在一个界面里完成。
这个产品思路让我想到在调研过程中一个有意思的对照:Anthropic 在做 Claude Managed Agents 的时候,技术博客里提到一个概念,他们把 Agent 的核心组件虚拟化成了 session、harness 和 sandbox 三层抽象,这是从技术架构的角度去思考如何让 AI 更好地运行。
GenSpark 做的是另一侧: 从用户工作流的角度去思考,如何让人和 AI 之间的协作最顺畅。
两条路径,一个朝着 AI 的效率极限走,一个朝着人的体验极限走。
GenSpark 选了后者,而且做得相当扎实。
2026,我们将去向何处?
Anthropic 在 3 月份发过一份报告,里面有一个数据让我印象很深:
目前许多工作角色中,依然有大量环节可以被 AI 自动化,而把这部分真正用 AI 接管,将释放出巨大的价值。
也许,这就是 2026 AI 员工这个赛道为什么热门的原因。
Anthropic 文档截图翻译|图片来源:Anthropic
为什么大厂都在抢这个赛道?
我觉得本质上抢的是入口: 当每一个人独特的工作流和对话记录留在了一个平台上,这些数据很难被迁移到其他地方。用户留下来,意味着持续的使用和消耗。这场仗打的不是功能比拼,而是谁能先成为用户的默认工作入口。
回到个体层面,工作中那些可以被自动化的部分,最终都会被 AI 接管:这个趋势已经不可逆了。就像我自己的工作流一样,资料收集、翻译、初步研究这些环节,GenSpark 4.0 已经能帮我完成得很好。我的精力可以更多地放在判断、决策和创造性的部分。
也许用不了多久,我们每个人手边都会有一个甚至多个 AI 员工: 也许是悟空,也许是 DuMate,也许是 WorkBuddy,也许是 aily。
但 GenSpark 4.0 给我的感受是, 它在「AI 员工应该长什么样」这个问题上,想得最完整,也做得最彻底。
写完这篇稿子,我在 GenSpark 4.0 里花的时间远远超过了测试本身:我发现自己不自觉地把越来越多的工作迁移到了这个平台上。
这大概就是一个好的 Agent 产品应该有的样子: 你不是因为它功能强大才去用它,而是用着用着发现,自己已经离不开了。
最后,2026 年 GenSpark 为所有用户提供 AI 聊天和 AI 图像功能的无限使用,集成了 Nano Banana 2、Gemini 3.1 Pro、GPT-5.4、Claude Opus 4.6 等多个顶级模型。
GenSpark 4.0,值得花时间去体验一下。
*头图来源: Genspark
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}